在2016年的微软Build开发者大会上,微软正式发布了其Azure云平台上的大数据处理服务,这一举措标志着微软在云计算和大数据领域的战略布局迈出了关键一步。此次发布不仅为全球的软件开发者和企业提供了强大的数据处理工具,也深刻影响了后续软件开发的范式与架构。
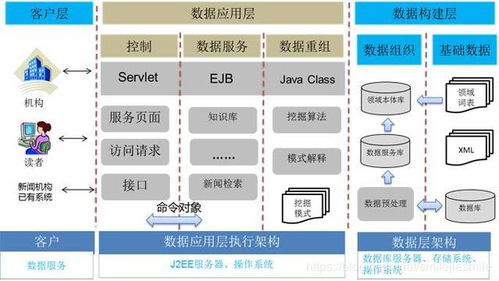
Azure大数据处理服务的核心在于其全面整合的生态系统。它涵盖了从数据采集、存储、处理到分析与可视化的全链条解决方案。例如,Azure Data Lake提供了无限扩展的数据湖存储,支持结构化和非结构化数据的高效管理;Azure HDInsight则基于流行的开源框架如Hadoop和Spark,为企业提供了托管式的大数据分析集群。Azure Stream Analytics实现了实时数据流的处理,而Azure Databricks(随后推出)进一步优化了数据工程和机器学习工作流。这些服务的协同工作,使得开发者能够快速构建和部署大规模数据处理应用,无需担忧底层基础设施的复杂性。
对于软件开发行业而言,这一发布带来了多方面的变革。它降低了大数据技术的入门门槛。传统的Hadoop或Spark部署需要专业的运维知识和硬件投入,而Azure的托管服务让开发者只需通过简单的配置即可启动集群,从而更专注于业务逻辑和算法开发。Azure大数据服务与微软的其他产品(如Visual Studio、.NET框架和Power BI)无缝集成,为开发者提供了熟悉的工具链,提升了开发效率。例如,开发者可以使用C#或F#在Azure Functions中编写数据处理代码,并通过Power BI实时可视化结果。
在应用场景上,Azure大数据处理服务迅速渗透到各个行业。在金融领域,银行利用其实时流分析检测欺诈交易;在零售业,企业通过分析客户行为数据优化库存和营销策略;在物联网(IoT)中,传感器数据被实时处理以监控设备状态。这些案例展示了大数据如何从“技术概念”转化为“业务驱动力”,而Azure平台正是这一转化的关键催化剂。
从技术趋势来看,Build 2016上的发布也预示了云计算与人工智能的融合方向。大数据处理为机器学习提供了燃料,Azure随后推出的认知服务(如文本分析和图像识别)正是建立在高效的数据管道之上。开发者可以轻松地将数据处理与AI模型训练结合,构建智能应用。例如,一家医疗初创公司可能使用Azure Data Lake存储患者数据,用HDInsight进行预处理,再通过Azure Machine Learning训练诊断模型,最终部署为可扩展的API服务。
微软在Build 2016上正式发布Azure大数据处理服务,不仅是其云战略的重要里程碑,也为全球软件开发社区注入了新的活力。它通过降低技术复杂度、提升集成度和拓展应用边界,推动了大数据技术的民主化。随着后续服务的不断演进(如Azure Synapse Analytics的推出),这一生态系统持续赋能开发者,帮助他们在数据驱动的时代中创新与成长。对于任何从事软件开发的个人或团队而言,掌握Azure大数据工具已成为提升竞争力的必备技能,而2016年的这次发布,无疑为这场变革按下了加速键。