随着大数据技术的快速发展,数据量的爆炸式增长对存储和计算能力提出了更高要求。传统的大数据架构往往将存储与计算紧密耦合,导致资源利用率低、扩展性差、运维复杂等问题。存算分离架构应运而生,而统一元数据与数据湖Catalog正是实现这一架构的核心支撑。
一、存算分离的挑战与需求
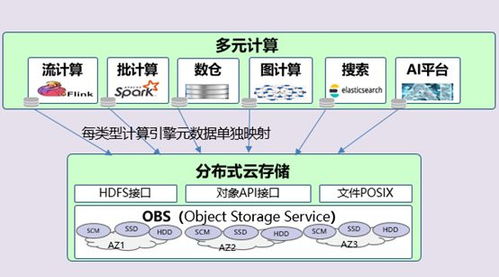
在传统大数据平台上,存储和计算通常部署在同一集群中,数据本地性虽能提升计算效率,但也带来明显弊端:资源难以独立扩展、存储格式受限、多引擎数据共享困难等。存算分离通过将存储层与计算层解耦,使两者能够按需独立扩展,大大提升了系统的灵活性与成本效益。分离后的数据如何高效管理、如何确保数据一致性、如何支持多样化的计算引擎访问,成为亟待解决的问题。
二、统一元数据的作用
元数据是描述数据的数据,包括数据的结构、格式、位置、权限等信息。在存算分离架构中,统一元数据管理能够为分布式存储系统中的数据提供全局视角。通过集中维护元数据,系统可以实现以下优势:
- 数据发现与目录化:用户和应用程序能够快速查找和访问所需数据。
- 多引擎支持:统一元数据使得不同计算引擎(如Spark、Flink、Presto等)能够无缝访问同一份数据。
- 数据治理与安全:通过统一的权限控制和审计机制,保障数据的安全性与合规性。
三、数据湖Catalog的关键角色
数据湖Catalog作为统一元数据管理的具体实现,是大数据存算分离架构中的“数据目录”。它本质上是一个元数据存储和查询服务,能够对接多种数据源(如HDFS、S3、ADLS等),并提供标准化的数据访问接口。其主要功能包括:
- 元数据抽象与标准化:将底层存储的细节封装起来,向上提供统一的数据视图。
- 数据版本管理与ACID事务支持:确保在并发访问场景下的数据一致性。
- 跨区域与多云数据集成:帮助企业整合分布在多个环境中的数据,实现全局数据治理。
四、实践案例与未来展望
目前,业界已有多个开源与商业产品支持数据湖Catalog功能,如Apache Hive Metastore、AWS Glue Data Catalog、Alibaba Cloud Data Lake Formation等。这些工具通过提供完善的元数据管理能力,有效支撑了存算分离架构的落地。例如,某电商企业通过引入统一元数据与数据湖Catalog,将其数据平台从传统的Hadoop集群迁移至云上对象存储,实现了存储成本降低40%的同时,计算资源弹性扩展能力提升3倍。
未来,随着数据湖技术的成熟,统一元数据与数据湖Catalog将进一步与AI、数据编织(Data Fabric)等新兴技术融合,推动大数据架构向更智能、更自动化的方向发展。企业应积极拥抱这一趋势,构建以数据湖为核心的新一代数据平台,充分释放数据价值。
统一元数据与数据湖Catalog不仅解决了大数据存算分离的技术难题,更为企业数据架构的现代化演进提供了坚实基础。通过它们,企业能够实现数据资源的统一管理、高效利用与敏捷创新,真正迈向数据驱动的未来。